Current research projects
Energy-efficient machine learning processors
We are designing highly energy-efficient machine learning processors by developing both hardware-friendly algorithms and low-power hardware design techniques. Our ultimate goal is to build practical machine-learning processors that exhibit both state-of-the-art algorithm performance and energy efficiency by finding the best algorithm-hardware combination. For instance, we developed a neuromorphic processor implementing an SNN (Spiking Neural Network), which achieved substantially better energy efficiency while closely matching conventional deep learning in accuracy.
Hardware-oriented deep learning algorithms
Conventional deep learning algorithms indeed demonstrate excellent performance across many tasks, but often they are not suitable for hardware implementation due to excessive amount of computation and memory requirements. We aim to optimize state-of-the-art deep learning algorithms to make them suitable for hardware implementation by significantly lowering computational overheads. We recently demonstrated a reliable low-precision training algorithm with minimal accuracy degradation, allowing for the use of lightweight arithmetic units and lowering memory access overheads.
Circuits for machine learning
Digital CMOS circuits offer very reliable operation and are easy to design with, but they have certain limits on the achievable performance and efficiency. We are trying to overcome this limitation by adopting various circuit techniques in machine learning systems. One example is in-memory computing circuits, which improve energy efficiency through analog or mixed-signal operation on various deep learning models.
Power management circuits
Power supply regulation is one of the key challenges in modern large-scale digital SoCs. We look into both on-chip and off-chip approaches to reliably regulate power supply while mitigating common design issues. In addition, we aim to adopt system-level analysis to minimize design overhead.
Analog front-end circuit for SiPM sensors
Typical radiation detecting sensors require a dedicated highly sensitive analog front-end. By implementing the front-end as an integrated chip (IC), we look forward to achieving high resolution performance, as well as low power consumption and compact die area. Furthermore, we aim to develop novel circuit techniques to compensate degrading effects when sensing signals from a large SiPM array. Application-specific design process will further optimize the whole system. This design is expected to be practically applied to current medical imaging applications, such as gamma camera and PET.
Recent research examples
8-bit Floating-Point Deep Neural Network Training Processor
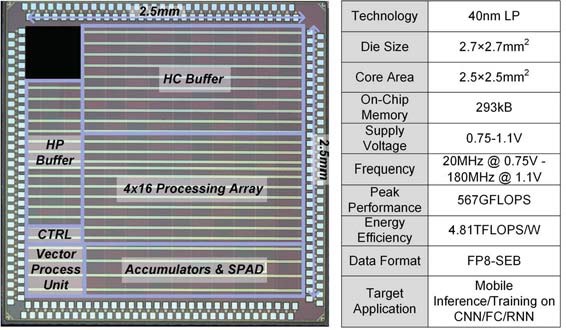
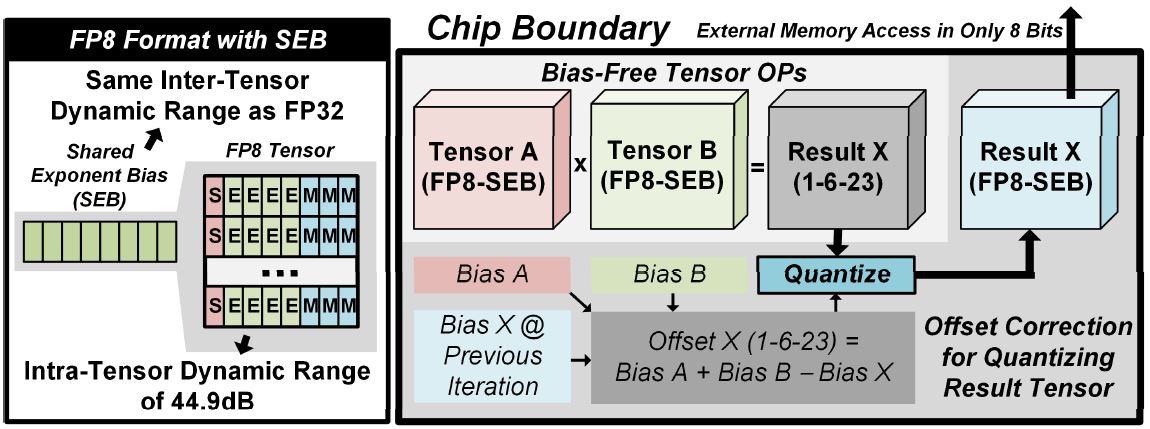
Due to the recent shift in the machine learning community towards using non-sparse activation functions such as Leaky ReLU or Swish for better training convergence, state-of-the-art models no longer exhibit the sparsity found in conventional ReLU-based models. Moreover, more difficult tasks such as image super-resolution require higher precision than plain 8-bit integers not just for training, but for inference without large accuracy degradation. To overcome such challenges, we developed a deep learning processor with support for efficient inference and training for various modern neural networks. Our key contributions are: (1) an 8-bit floating point data format with shared exponent bias (FP8-SEB) for robust training in low precision, (2) a processing architecture employing 24-way Fused Multiply-Add (FMA) trees and high-precision accumulators that improves training accuracy and energy efficiency, and (3) 2-D routing scheme on input/output points of processing element array for flexible training of various models with minimal hardware overhead. Based on these contributions, our neural network training processor achieves 4.81TFLOPS/W energy efficiency, 567GFLOPS performance, and robust training on various models including Generative Adversarial Network (GAN), Long-Short-Term-Memory (LSTM), transformer models, as well as Convolutional Neural Network (CNN).
Publications: ISSCC 2021, JSSC 2022
Awards:
– Gold Award (1st place in circuit design), Samsung Humantech, 2021.
– Best Design Award, ACM/IEEE International Symposium on Low Power Electronics and Design, 2021.
Energy-efficient neuromorphic processor with on-chip training
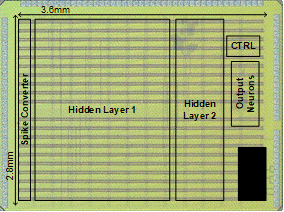


Neuromorphic computing algorithms such as SNN (Spiking Neural Network) offer great energy efficiency, but they are not considered practical solutions yet due to low algorithm accuracy. In this work, we proposed a new neuromorphic computing algorithm based on bio-plausible approach, which provides similar performance to SGD-based learning scheme. By combining a well-optimized architecture to further improve computation efficiency, we designed a ultra-low power on-chip trainable neuromorphic processor for classification tasks. Training energy of 254.3 nJ/image is achieved through a hardware-oriented direct feedback algorithm, out-of-order weight updates, and an update-skipping mechanism. During prediction, the processor achieves 97.83% MNIST recognition accuracy with 236.5 nJ/prediction. This result demonstrates a 7.5% training energy overhead, while providing superior energy efficiency than recent inference-only designs.
Publications: ISSCC 2019, JSSC 2020
Media coverage: Dong-A Ilbo (Korean Newspaper)
Low-dropout regulator with high efficiency and wide operating range
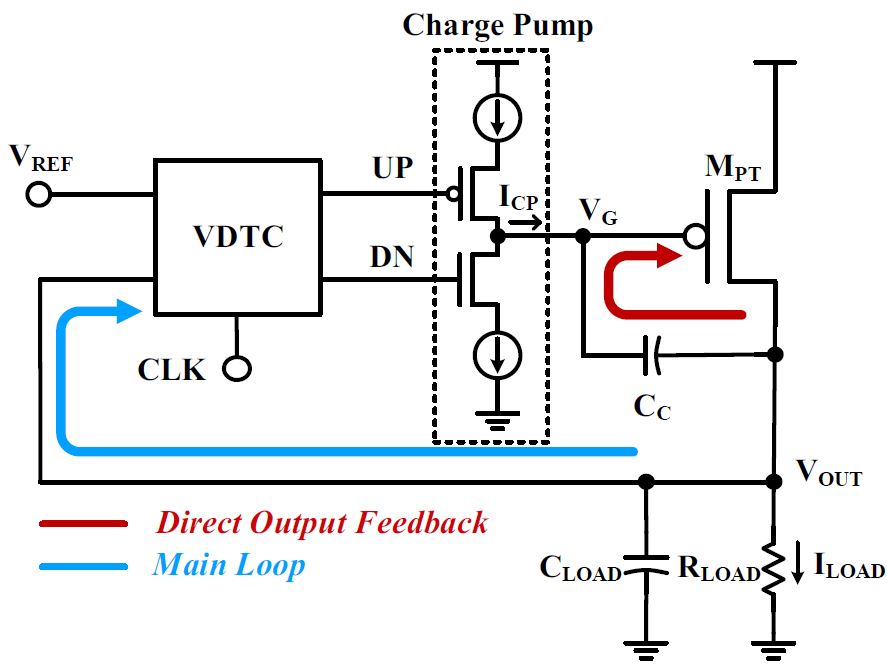

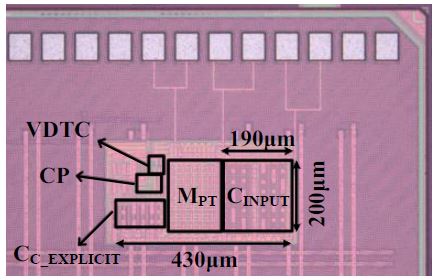
Large-scale digital SoCs must be accompanied by a reliable, efficient power management system. Low-dropout regulator (LDO) is one of the key blocks in those systems, where it must generate a constant output voltage under a wide range of input voltage and load current. We proposed a new LDO topology using a voltage-difference-to-time converter and direct output feedback path, and the design combines the advantages of conventional digital and analog LDOs. The fabricated LDO achieves 0.202fs FOM, which is significantly lower than prior works.
Publication: TCAS-II 2021
Radiation hardening by design
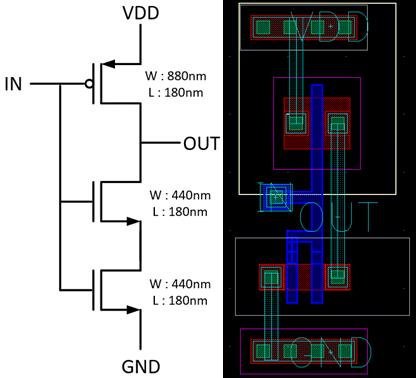


Under radiation emitting circumstances, high energy particles induce accumulation of holes in the oxide. The accumulated holes modify transistor characteristics such as threshold voltage, degrading hardware reliability. In order to avoid transistor malfunction in a circuit, radiation hardening by design (RHBD) techniques have been actively studied. In this project, we applied several topologies to an inverter which is a basic building block of all digital systems, and experimentally analyze the reliability of each circuit topology under high radiation dose. Measured results confirm that the stacked NMOS topology performs best, reducing switching point variation by >10x and average power by 20% at the expense of 30% area overhead.
Publication: NIMA 2020
Please note that the completed projects shown below were conducted at the University of Michigan (Advisor: Prof. Dennis Sylvester) and MIT (Advisor: Prof. Anantha Chandrakasan).
Navigation system for the visually impaired


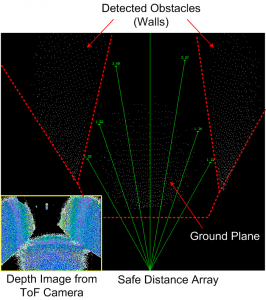


In this project, we developed a fully-integrated navigation system for the visually impaired. Since processing 3-D imaging data using exsiting algorithms is computationally expensive, commercial off-the-shelf processors are not able to process 3-D data in real time. To tackle this issue, we designed a highly energy-efficient vision processor tailored for general 3-D image data processing algorithms. By designing a new hardware architecture as well as optimizing conventional algorithms further, the processor fabricated in 40nm CMOS technology consumes only 8mW while processing 30fps 3-D input video stream in real time. We also implemented a fully-integrated navigation system and confirmed its functionality in various experiments.
Publication: ISSCC 2016
Selected media coverage: EE Times, Tech Times, Qmed, The Daily Dot
Face recognition system for mobile platforms

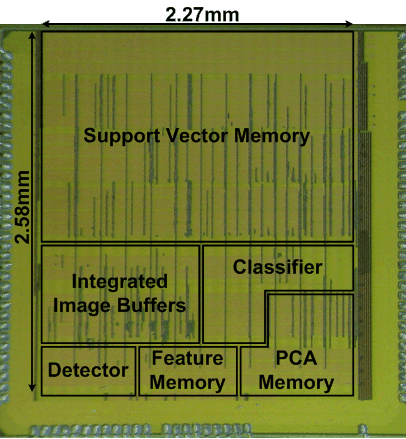
Face detection and recognition are now available on many mobile platforms. For instance, facebook app can reliably detect faces from uploaded photos. However, we wanted to take one step further and design a complete standalone face recognition system that has both face detection and recognition features and processes input video in real time. Based on classical but very reliable algorithms including cascade classifiers and Support Vector Machine (SVM), we optimized hardware architecture to minimize processing overheads. In addition, we proposed a new SRAM design tailored for this specific application to tackle the issue of large leakage current in advaned CMOS processes. The fabricated design consumes 23mW while processing HD video with 5.5fps throughput.
Publication: Symposium on VLSI Circuits 2015
Syringe-implantable ECG monitoring device
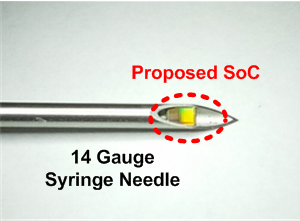


With continuous semiconductor technology scaling, recently small form factor implantable biomedical systems gained lots of attentions due to its enhanced computation capacity. In this project, we implemented a syringe-implantable ECG monitoring system primarily for arrhythmia detection. The system has a powerful ARM Cortex-M0 paired with custom digital signal processing blocks, which delivers both enough computing power and flexibility. The proposed system only consumes 65nW while monitoring ECG waveforms continuously and we confirmed its functionality in the experiment using a live sheep heart.
Publications: ISSCC 2014, JSSC 2015
Feature extraction accelerator
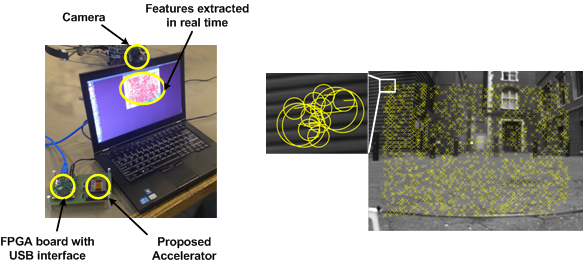
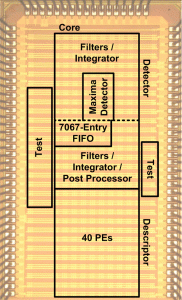
Visual feature extraction is a method to extract useful information from input image or video, and this information can be later used in other algorithms including object recognition and pose estimation. Since it is a key part in computer vision and generally requires a large amount of computation, we designed a specialized accelerator to significantly reduce processing overhead. Starting from original Speeded-Up Robust Features (SURF) algorithm we modified it from hardware design perspective, which resulted in more hardware-friendly algorithm. We also proposed a low-power robust FIFO design to mitigate tremendous amount of leakage power in low operating voltages. The proposed design provides 3.5x efficiency improvements than state-of-the-art designs.
Publications: ISSCC 2013, JSSC 2014
Media coverage: IEEE Spectrum
Energy-efficient FFT processor
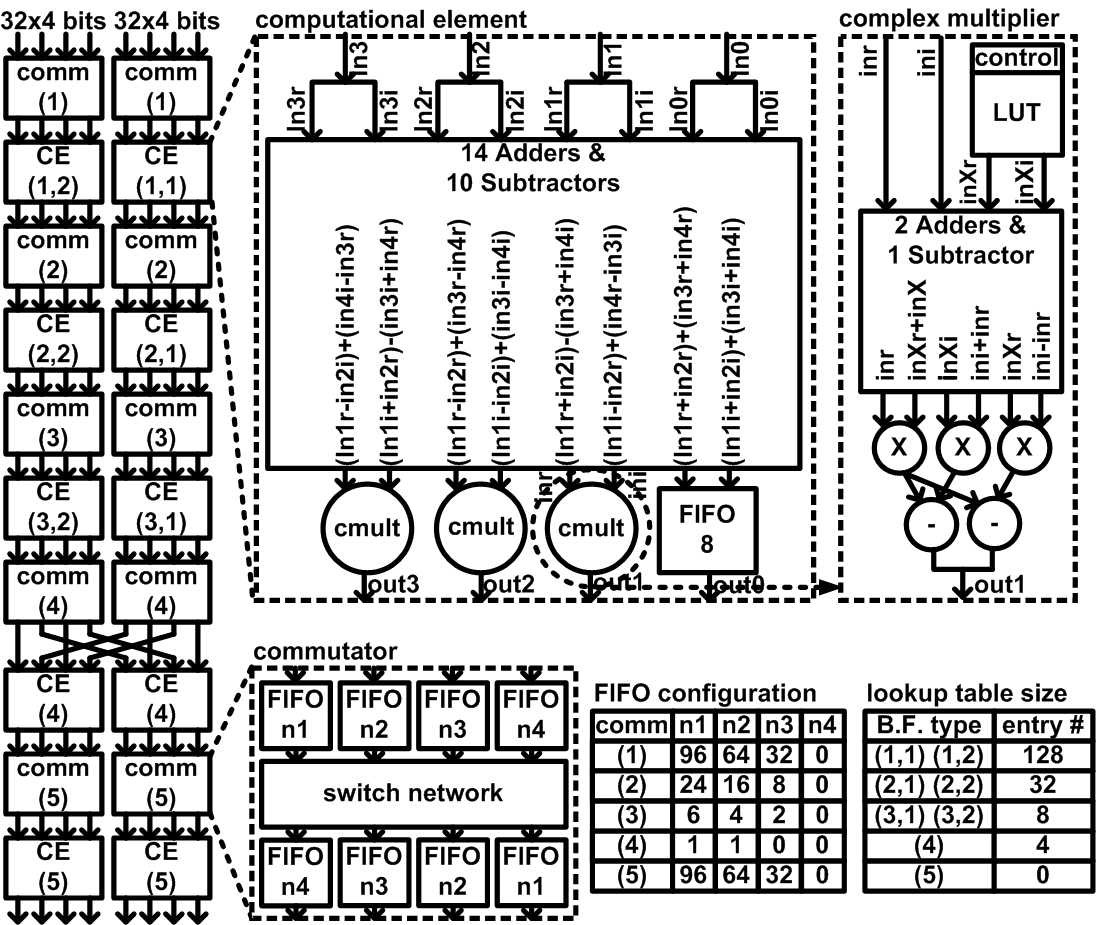
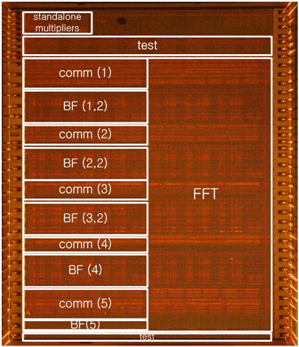
Fast Fourier Transform (FFT) is one of the most famous digital signal processing algorithms used in many platforms. In this project, we targeted achieving maximum energy efficiency for the given algorithm in order to increase the lifetime of battery-powered systems. We first developed a low leakage, energy-efficient parallel FFT architecture. This architecture was applied to the final FFT processor along with a novel circuit technique called “super-pipelining”, resulting in 2x better energy efficiency than previous works.
Publications: ISSCC 2011, JSSC 2012